SciRA
Abstract
A wide variety of academic papers are published daily and searching for related literature can be a burden. SciRA, short for Scientific Research Smart Assistant is a smart platform able to provide an innovative experience regarding the references between papers. It integrates various data sources such as DBLP, Colinda, ACM, arxiv and DBPedia datasets, taking advantage of 2012 ACM Computing Classification System and offers a platform to upload and manage new publications, providing a recommendation system based on user's search history. The big amount of data provided by the platform can be filtered by a series of custom attributes tailored to each user's needs.
Motivation
In the last years, the term Semantic Web receives more and more attention. With the variety of search engines available it is fairly easy for a human to search for academic literature but, searching for related papers is still a concern. SciRA incorporates the Semantic Web so that the data related to a scientific paper can be easily processed by machines. There are various linked data sets available on the internet, and SciRA incorporates these datasets alongside with its own publication platform, exposing a SPARQL endpoint to allow the user to retrieve data from all its sources. The platform is intended to be an invaluable resource while researching on a given topic, but can also be used by newcomers in learning a given subject.
Architecture
In the first section we briefly described the main goals of the application. The proposed project is based on a fat client - thin server architecture, exposing multiple independent microservices providing a variety of functionalities such as publications querying, user management, recommendation system, graph visualization of publications and authors relations. SciRA has three main components which are described in detail in the next subchapters:
- Client: web pages that communicate with the server's exposed API. Can also be implemented on different platforms (such as mobile devices).
- Server: based on multiple components, processes client's requests, fetches information from external linked data sources and generates recommendations accustomed to each user.
- Database: stores information about subscribed users and their publications.
Server
The server is based on the MVC (Model - View - Controller) design pattern:
- Controller: interacts with the clients through an API, using JSON-LD, and decides which microservices to use for processing the requests.
-
Model: has multiple components focusing on different services:
- Search: processes search input from the client, having three different implementations: Simple (used for casual searches, combining keywords to find matching publications), Advanced (combining multiple advanced filters in order to constraint the search domain for more specific results), Editor (exposes an endpoint where each subscribed user can submit his own SPARQL query).
- SPARQL Parser: based on the input from the search component, builds the SPARQL query tailored to each endpoint (Colinda, DBLP, ACM, Arxiv, DBPedia or the local dataset) and retrieves and combines the pieces of information acquired from the linked data endpoints.
- Recommendation System: used in generating recommendations for a specific user and for providing related results for queried publications. The algorithm executes a fuzzy search taking into consideration publications that have related topics, tags, authors, publication dates etc.
- User Manager: Manages all interactions of a user with the local database including authentication, profile editing, publication uploading etc.

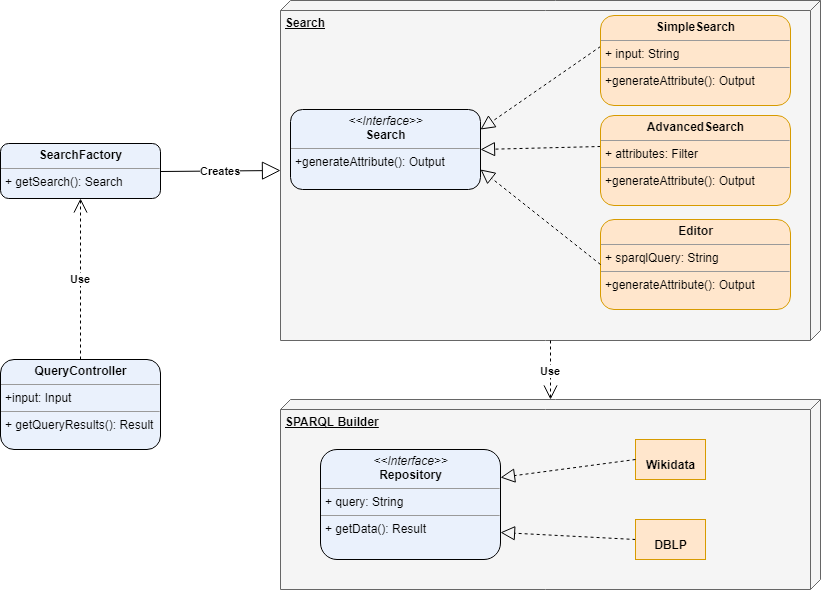
The figure below presents the class-diagram which describes the application by showing the system's classes, their attributes, methods and relationships among objects. The Search and the SPARQL component are implemented using the abstract factory design pattern, providing generic interfaces (Search, Repository) for creating families of related or dependent objects without specifying their concrete classes.
API
The server exposes two main API endpoints corresponding to the two main controller components (Search and User Management). All client - server communication is done via the API which uses JSON-LD. We also provide an OpenAPI 2.0 specification that describes in detail each available path. Offering multiple HTTP methods through which the API can be used, the application integrates the whole CRUD spectrum.
The user component provides all the necessary operations for user management (user creation, logging in, profile updates, publication view history and recommendations). A short description of each available operation can be seen in the figure below.

The publication component handles all queries related to publications searching and recommandations. It is composed of three components which correspond to the three search components in the server (Simple Search, Advanced Search and Raw SPARQL Search) and also has a route for the recommendation system, in which, given a publication, similar ones are returned.

Client (Front-end)
The client is a RDFa webpage (HTML+RDF). The implementation is independent from the server, all communication being achieved through JSON-LD APIs. The webpages are updated dynamically using javascript to render the information in an user friendly manner.
The interface is simple and intuitive, all the pages following the same layout. The home page is made of a search bar having an additional button which allows the user to use the advanced search functionality. The result page consists of a simple table, displaying the outcome of the querry.

There are two options for viewing each result, a detail page (information about the publication and related documents) and a graph representation of all the relationships. There are also specific pages for the interaction with the user (login, sign up, update profile etc) and a custom form for uploading a new paper.

Conclusions
To sum up, Scientific Research Smart Assistant aims to be an invaluable tool while researching on a specific topic and also provides a learning support for students who want to improve their knowledge. Offering an innovative visual experience, SciRA aids in finding useful related publications, tailored to the users needs.
References
- SPARQL Query Language for RDF,
- PR RDF schema,
- OpenAPI-Specification,
- RDF - cadru de descriere a resurselor Internet bazat pe XML,
- What is scholarly HTML,
- How to write a technical report,
- W3C Scholarly HTML,
- DBPedia,
- Schema.org,
- DBLP,
- arXiv,
- ACM,
- Colinda,